Я не робот! Как интернет-пользователям приходилось доказывать, что они люди, попутно решая чужие проблемы
Я определенно не робот. На мне есть кожа, под ней — органические кости и мышцы, сухожилия и артерии, кровь и лимфа. В черепной коробке даже имеется мозг, благодаря которому я осознаю себя человеком, умею принимать решения, решать головоломки, ломать голову над бытовыми проблемами, а порой и создавать себе проблемы, которые не поддаются логичному и разумному толкованию. Я определенно не робот.
Однако мой компьютер с завидной частотой заставляет меня доказывать обратное. Собрался что-то поискать в интернете? Введи капчу. Логинишься в почтовый аккаунт? Будь добр решить капчу. Входишь в онлайн-игру? Капча тут как тут.
И знаете, что во всем этом самое неприятное? Иногда с первого раза пройти эту капчу не удается. Она стала заметно сложнее с тех пор, когда я увидел ее в интернете впервые в середине нулевых.
Что такое капча на самом деле? Почему она так усложнилась за последние годы? И как капчу используют для того, чтобы учить их злейших врагов — роботов? Сегодня поговорим об этом.
Нигерийские принцы
Начнем с того, что капча — это аббревиатура. Точнее, акроним — слово, которое можно произнести слитно и которое представляет собой сокращение. КГБ — это аббревиатура, вуз — это акроним. Капча происходит от английского CAPTCHA — Completely Automated Public Turing test to tell Computers and Humans Apart. Перевести это можно как «полностью автоматизированный общедоступный тест Тьюринга, позволяющий отличить компьютеры от людей». Если все это сократить, получится аббревиатура, а не акроним.
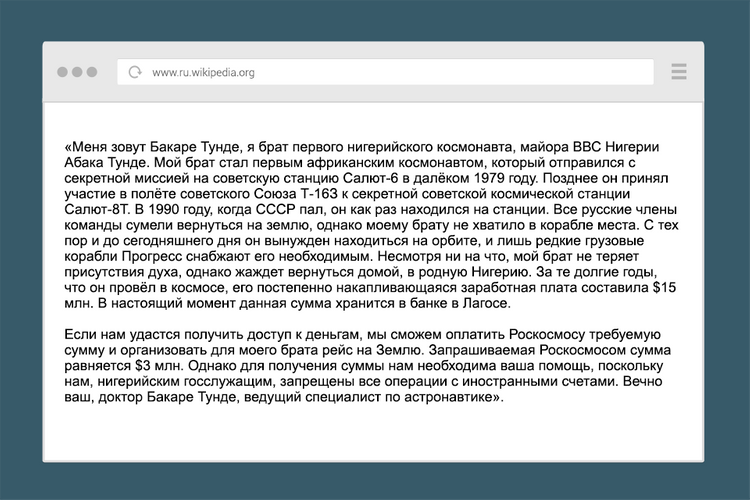
В интернете ранних нулевых большой проблемой был спам — массовые рассылки рекламных писем на самую разную тематику — от образования до медикаментов и контрафакта.
Часть этих писем были мошенническими. Спам-боты регистрировали тысячи аккаунтов, с которых и велась рассылка. Например, от «нигерийских принцев», которым нужна небольшая сумма денег, чтобы осыпать адресата несметными богатствами. Рассылки эти были столь массовыми, что нигерийские спамеры стали частью интернет-фольклора. В 2005-м им присудили Шнобелевскую премию по литературе за создание колоритных персонажей, а в следующем году Forbes включил одного из выдуманных «нигерийских принцев» в список богатейших вымышленных персонажей.

Первые варианты капчи
Почтовым сервисам нужно было срочно придумать что-то, чтобы остановить этот бесконечный поток спама, который нагружал серверы и мешал людям пользоваться услугами почтового ящика. Так и были изобретены первые легкие тесты, которые мог бы пройти человек, но с которыми было сложно тягаться компьютеру. Тесты действительно должны были быть легкими, чтобы их смог пройти любой человек вне зависимости от его образования, возраста или местонахождения.
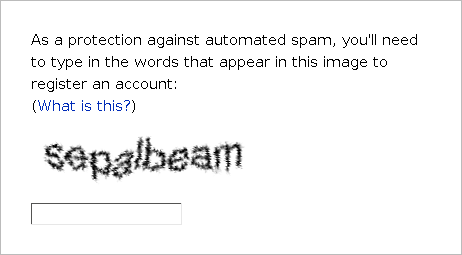
Поэтому изначально большинство капч базировались на самом простом, что умеет человек. Раз он вышел в интернет, значит, он умеет читать. Ему не составит труда прочитать растянутые и каким-либо образом искаженные буквы в осмысленных и общеизвестных словах.
Да, компьютеры в нулевых уже умели в «оптическое распознавание символов». Существовало ПО, которое могло распознать напечатанный и отсканированный текст — для перевода книг и документов в электронный вид или автоматизации систем учета в бизнесе. Однако оно довольно часто сбоило и не справлялось должным образом со всеми отсканированными буквами.
Мы умеем читать тексты, искаженные под разными углами, в различных условиях освещения, перечеркнутые и растянутые. Некоторые даже справляются с текстами, написанными врачами в рецептурных листках. Ботам нулевых такое давалось куда сложнее.

Однако они не стояли на месте. Довольно быстро было разработано несколько путей обхода капчи. Порой для распознавания использовали дешевый человеческий труд, банальные ошибки в реализации капчи на ресурсах и машинное обучение. Например, у некоторых систем CAPTCHA был ограниченный набор слов, у других — слова фиксированной длины. Один человек на сдельной зарплате мог раскусывать сотни таких головоломок в час, пополняя базу спам-ботов.
Все это напоминало гонку вооружений: разработчики CAPTCHA придумывали все более сложные алгоритмы для генерации искаженных текстов на изображениях, разработчики спам-ботов довольно быстро подстраивались под меняющиеся условия. Дошло до того, что на черном рынке услуга по распознаванию миллиона таких картинок стоило всего около $1000.
С этим надо было что-то делать.
reCAPTCHA
В 2005 году от создателей оригинальной капчи (хотя за авторство этих тестов велись долгие и упорные битвы) вышла reCAPTCHA — новая и улучшенная версия теста.
Ее автор, гватемальский ученый и предприниматель Луис Фон Ан, в какой-то момент осознал, что «невольно создал систему, которая растрачивала с шагом в десять секунд миллионы часов самого ценного ресурса — циклов человеческого мозга». Все-таки на решение CAPTCHA нужно было время, и многих она раздражала. А потому Луис решил, что было бы неплохо, если бы новая версия конвертировала потраченное время пользователей во что-то полезное.

Пользователю предлагалось распознать два слова. Одно генерировалось системой reCAPTCHA автоматически, так что она знала правильный ответ. Второе бралось из книги или древнего архива газеты The New York Times, и система не знала, что же за слово было на второй картинке. Если пользователь вводил первое слово правильно, то система предполагала, что и второе слово он прочитал верно.
Потом это второе слово предлагалось разгадать другим пользователям reCAPTCHA. И если большинство из них писало одно и то же, то в системе этот ответ утверждался и в дальнейшем ассоциировался со словом на картинке. Если же его слишком часто пропускали, то оно помечалось как нечитаемое и исчезало из системы.
reCAPTCHA использовалась столь массово, что каждые четыре дня благодаря пользователям, которые не особо вдавались в подробности, оцифровывался годичный объем статей NYT.
В 2009 году Google приобрела разработчиков reCAPTCHA и поставила на поток оцифровку книг. Система показывала 100 млн окон с проверкой ежедневно, массово использовалась компаниями Facebook, Twitter, новостными ресурсами.
Да будь ты проклята, капча!
Спустя три года зародилась самая мерзкая, отвратительная и ужасная версия reCAPTCHA. В Google подумали, что замечательной идеей будет подсовывать пользователям для проверки не слова, а фотографии из сервиса Google Street View. Таким образом «корпорация добра» решила улучшить данные на своем сервисе Google Maps, заставляя пользователей определять названия улиц и служебные адреса.
Нет, первое слово в тесте оставалось прежним — сгенерированным системой. А вместо второго система подсовывала маленькие картинки с размытыми номерами домов, названиями улиц и дорожными знаками.

Таким образом проходило обучение системы компьютерного зрения, которую разрабатывали в Google, — опять же бесплатно, за счет времени, которое тратили на это пользователи сети. Некоторые ресурсы даже доплачивали Google, если на их страницах осуществлялось более 1 млн запросов к системе reCAPTCHA в месяц.
Правда, в какой-то момент технологии искусственного интеллекта, натасканные на reCAPTCHA, умели читать максимально изуродованный текст с точностью 99,8%, тогда как среди обычных пользователей этот процент был равен 33. Компьютеры обошли нас в тесте, в котором долгое время мы оставались лидерами.
А Google шла все дальше. Со временем к небольшим вырезкам из картинок с Google Street View добавились двойные тесты, на которых пользователи должны были выбрать всех котиков или индеек. Дальше задачи усложнялись: приходилось находить дорожную разметку, автомобили, велосипеды, лодки и еще кучу объектов, на распознавание которых Google натаскивала свои беспилотные автомобили.

Это бесило не только простых пользователей. Google, по сути, эксплуатировала неоплачиваемый труд сотен миллионов юзеров по всему интернету.
noCAPTCHA
Это начали понимать и в Google. И в 2014 году там решили обновить систему, напрямую попросив пользователей поставить галочку рядом с текстом «Я не робот».
Эта новая система активно считывает все взаимодействия пользователя с окошком CAPTCHA — до, во время и после нажатия на чекбокс, — чтобы определить, что он не является ботом.

По сути, система следит за нашим поведением на странице с капчей. Находясь на ней, мы проходим секретный тест, в котором компьютер решает, что мы ведем себя в интернете достаточно человечно, чтобы пропустить нас дальше: не кликаем безумно по странице, не печатаем абзацы текста всего за несколько секунд. Во-первых, HTML-код кнопки noCAPTCHA не похож на кнопку, он просто выглядит как любая другая часть страницы, поэтому ботам трудно даже найти нужное поле. Во-вторых, это делается с помощью JavaScript, а не обычной HTML-формы. Большинство ботов не работают с JavaScript. Google также изучает поведение пользователя, например, активность мыши, используемый браузер, ваш IP-адрес и, возможно, на каких других страницах была замечена ваша активность, чтобы выяснить, действуете ли вы как бот.
Звучит достаточно жутко. Но в сети уже давно нельзя сидеть со спокойной душой, так как отслеживать наши действия интернет-корпорации научились прекрасно.
Впрочем, старые методы проверки не ушли далеко. Если система все-таки засомневается в поведении пользователя, она вывалит ему все те же тесты с распознаванием объектов на картинках. На очень плохих и маленьких картинках. Но такова уж цена возможности зваться человеком в интернете.
С доставкой к миске — много видов и брендов кормов для кошек в Каталоге

Наш канал в Telegram. Присоединяйтесь!
Есть о чем рассказать? Пишите в наш телеграм-бот. Это анонимно и быстро
Перепечатка текста и фотографий Onliner без разрешения редакции запрещена. nak@onliner.by